A major problem many businesses face today is the inability to leverage data trapped inside scanned documents and images. Whenever a business relies on such data, manually re-keying the data becomes the biggest bottleneck and adversely affects the business.

In such scenarios, we need data-entry automation that helps extract information from scanned documents and automate document-based business processes.
But the problem is two-fold. The challenge is not just to extract information from scanned documents but also to extract it accurately. This becomes even more challenging when the data inside these scanned documents and images is tabular and graphical in nature and needs to be structured correctly.
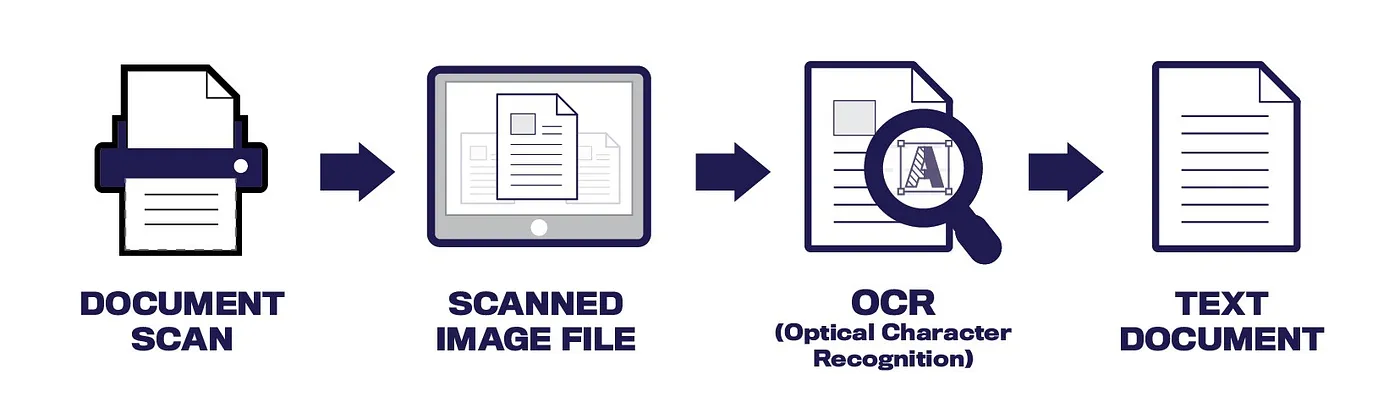
Quick Overview of the Extraction Process
A. OCR — To accurately extract data from scanned documents, Optical Character Recognition (OCR) is needed. A combination of pattern recognition and image processing techniques are used to convert batches of scanned files to excel sheets or any other document format.
B. Information extraction (IE) — Information Extraction is the process of extracting domain-specific information from textual data sources. Bank Statements, Legal Acts, Corporate Reports, Medical Records Government Documents are other free flowing textual sources from which information extraction can provide structured information.
Gathering structured data from texts, Information Extraction enables -
- The automation of tasks such as smart content classification, integrated search, management and delivery.
- Data-driven activities such as mining for patterns and trends, uncovering hidden relationships etc.
Factors Affecting OCR
Receipts often are printed on thermal paper by a basic printer. That receipt might get wrinkled or folded and the quality of the scanned image reduces. Try to use the highest quality document possible. If an original is of low quality — for example, the ink is too light, the paper is not flat and white (or the text otherwise does not contrast highly with the background) — an OCR engine will have a difficult time discerning the text from any noise surrounding it.
Sometimes the images are not clear i.e. the OCR engine knows there is data but cannot accurately read it
Similarly, the quality of a document acquired by a computer for OCR will influence the quality of OCR output. If the original document is:

- Wrinkled, torn, or otherwise damaged, faded or otherwise aged, discoloured, smudged (or the text is otherwise obfuscated or distorted)
- Printed with low-contrast or coloured ink
- Rendered with nonstandard fonts or in human handwriting,
- Printed on specific types of paper that decrease crispness and contrast between the background and foreground in the resulting scan.
DOs:
- Make sure that the page fits entirely within the frame.
- Make sure there is enough light (preferably daylight). In artificial lighting, use two light sources positioned to avoid shadows.
- Turn off the flash to avoid glare.
- The recommended resolution for best scanning results for OCR accuracy is 300 dots per inch (dpi). Brightness settings that are too high or too low can have negative effects on the accuracy of your image. A brightness of 50% is recommended. The straightness of the initial scan can affect OCR quality.
- Position the lens parallel to the plane of the document and point it toward the centre of the text. At full optical zoom, the distance between the camera and the document must be sufficient to fit the entire document into the frame. Usually this distance will be 50–60 cm.
- If possible, avoid shaking and remove jitter.
- If feasible, use a white sheet of paper to set white balance while taking an image. Otherwise, select the white balance mode which best suits the current lighting conditions.
DON’Ts:
- Do not put characters with very large or very small font sizes on paper. This can make the most important character unavailable for text-based system.
- A lot of languages have special characters, unless the correct OCR locale is loaded, those characters can be lost. Try avoiding such languages.
- OCR is case-sensitive so if you write “CAT or cat” it will end up with same results. So, make sure you check formatting of the document or image before uploading.
- Try avoiding using logos and symbols because glyphs do not get converted to OCR and it will leave the space empty.
Factors Affecting Information Localisation & Extraction
- Skew & Orientation

- There are a variety of circumstances in which it is useful to determine the text skew and orientation:
- Improves text recognition. Many systems will fail if presented with text oriented sideways or upside-down. Performance of recognition systems also degrades if the skew is more than a few degrees.
- Simplifies interpretation of page layout. It is easier to identify text lines and text columns if the image skew is known or the image is de-skewed.
- Improves baseline determination. The text line baselines can be found more robustly if the skew angle is accurately known.
- Improves visual appearance. Images can be displayed or printed after rotation to remove skew. Multiple page document images can also be oriented consistently, regardless of scan orientation or the design of duplex scanners.
- OCR Errors

- Many errors that are generated by OCR systems can be traced back to low quality scanning or deteriorated printed materials. Sometimes that original physical paper is no longer available to re-do the scanning.
- In some documents, content viewable in the document images were either partially or completely lost in the OCR process. Also, useful context information would occasionally be lost as well.
- In some documents handwritten content appears which is not recognised by the OCR. Because of these problems recognising handwritten content requires us to follow an entirely different approach.
- Document Structure
- Extracting data which has a specific template such as bills, receipts, insurances etc. are extremely common and critical in a diverse range of business workflows.
- Putting very large or very small fonts in the document can affect the data extraction.
- In some documents, text is located at random locations which can end up affecting OCR when it is being processed.
- Format of the text is very important factor. If the formatting of the document is not up to the mark it might end up extracting wrong information or might leave the text field blank.
DOs:
- For skew measurement, the operations should be fast, with a computation time relatively independent of image content. They should be accurate, with a consistent error less than 0.1 degree to satisfy all applications.
- When your application receives an image for recognition, one of the first steps can be checking the image resolution. If the resolution is too small (lower than 150 dpi), some image details might be lost, and the recognition quality will deteriorate. If, on the other hand, the resolution is too great (greater than 600–700 dpi), loading and processing the image will take more time, while the recognition quality will not be materially improved.
- Make sure to use a reliable scanner that provides a good quality scan for more accurate data extraction.
- All lines should be connected without breaks in between the text lines
- Maintain a consistent pattern in which the information to be collected will be located.
DON’Ts:
- Do not click photos of documents from tilted angles
- Avoid using a low-resolution camera when clicking a photo
- Avoid using colourful printed copies for documents
- Avoid changing the format of the document too often
OCR is the most important aspect of your workflow management and automation system. It improves productivity and bridges the gap between humans and machines by enabling access to crucial data trapped in important documents.
